Qualitative Results
To illustrate how our system adapts to test-time information, we present intermediate outputs of the framework, including the failed plan and interaction, the newly generated plans, the selected plan, and the final execution that improves task completion. Our system operates in three stages:
Task: Push Bar






Task: Pick Bar






Task: Turn Faucet






Task: Open Box






Video Generation with State Embedding
Our system generates videos conditioned on the state embedding derived from past interaction video. We show the generated videos for the same task but with and without conditioning on the state embedding. The state embedding helps the system to generate videos that are more consistent with the underlying system parameters.
Task: Push Bar









Task: Open Box









Task: Pick Bar









Task: Turn Faucet









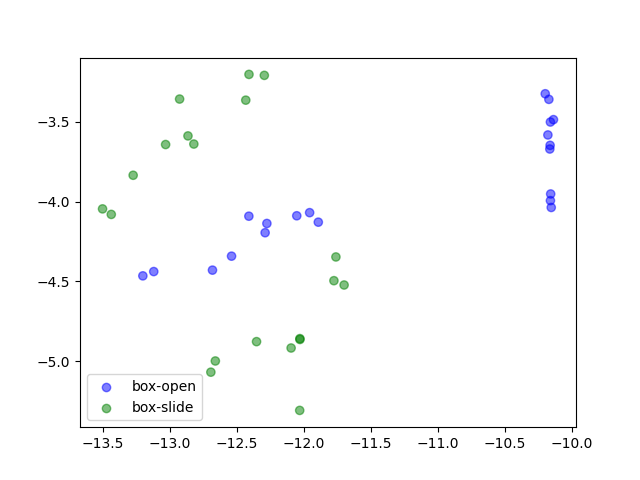
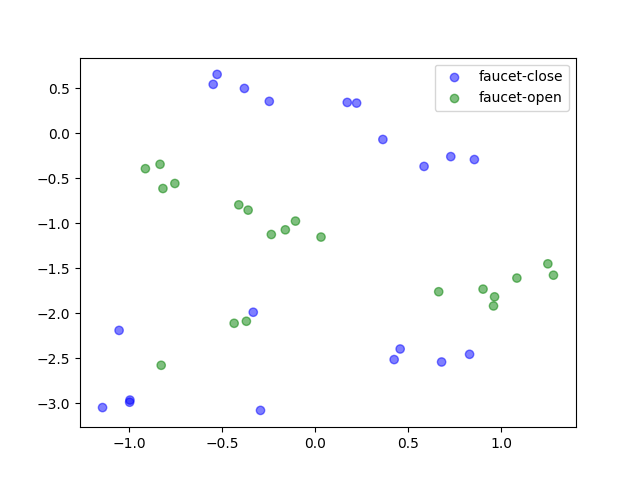
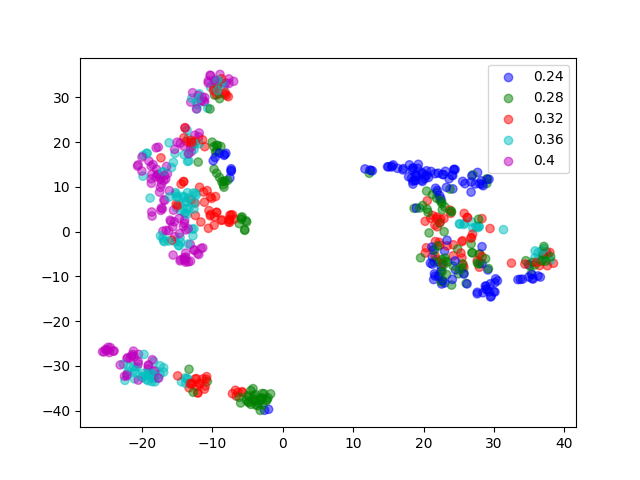
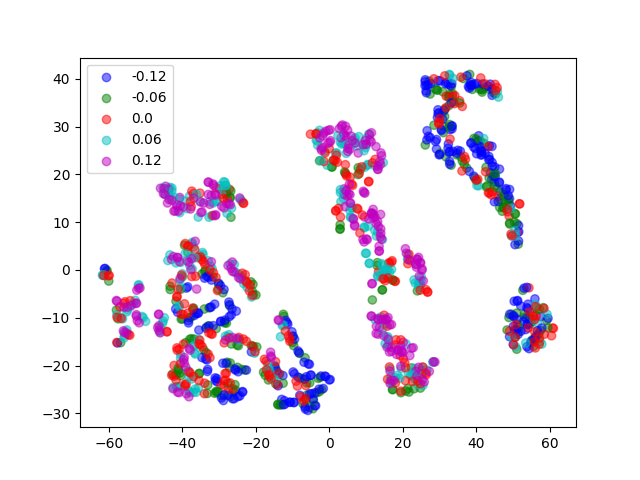
t-SNE Visualization on System Parameters
We visualize the distribution of underlying system parameters using t-SNE applied to state embeddings extracted from interaction videos. The colors indicate the ground-truth system parameters.
For tasks with discrete modes (e.g., Open Box, Turn Faucet), the clusters are well-separated. In contrast, the distribution is more complex for tasks with continuous modes (e.g., Slide Brick, Pick Bar), which may help explain why learning to identify system parameters for these tasks is more challenging and tends to require more data.